微服务架构下的数据处理服务 核心概念与实践
在当今的软件开发领域,微服务架构已成为构建复杂、可扩展应用的主流范式。它将单一庞大的应用拆分为一组小型、独立的服务,每个服务围绕特定的业务能力构建,并可以独立开发、部署和扩展。在这一架构中,数据处理服务扮演着至关重要的角色,它负责数据的存储、处理、转换与供给,是连接业务逻辑与数据持久层的核心枢纽。
微服务架构的核心特征
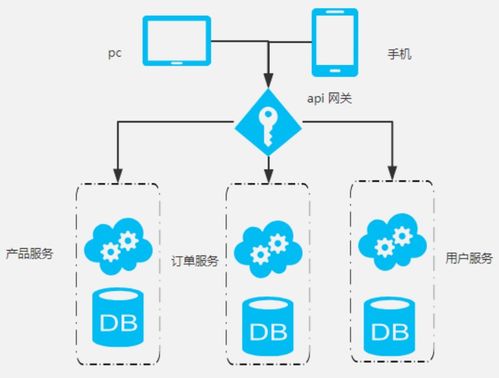
微服务架构强调服务的自治性、技术异构性、去中心化治理以及通过API进行通信。每个微服务通常拥有自己独立的数据库,这有助于实现数据封装和松耦合。这种数据的分散性也带来了新的挑战,尤其是在数据一致性、查询聚合和事务管理方面。
数据处理服务的定位与职责
在微服务生态中,数据处理服务并非单一实体,而是一类服务的统称,其核心职责包括:
- 数据持久化与存储:为特定的微服务提供专属的数据存储(如SQL或NoSQL数据库),确保数据模型的独立性和服务边界的清晰。
- 领域数据处理:实现服务内部的业务逻辑,对数据进行计算、验证、转换和聚合,以满足特定业务场景的需求。
- 数据同步与集成:在服务间数据需要共享或保持一致性时,通过事件驱动架构(如发布/订阅模式)或API调用,实现数据的异步同步,例如使用Change Data Capture (CDC) 技术捕获数据库变更并广播事件。
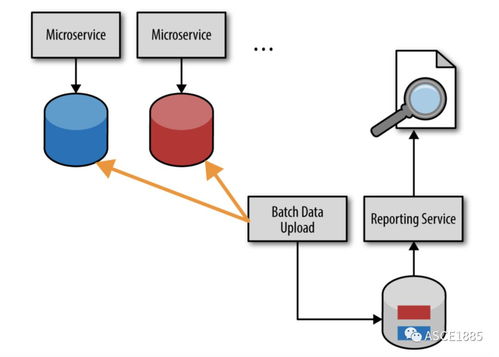
- 数据查询与API暴露:提供清晰、高效的API(如RESTful API或GraphQL端点),供其他服务或前端应用消费处理后的数据。对于复杂的跨服务查询,可能需要通过API组合模式或构建专用的数据聚合服务(如Backend for Frontend, BFF)来实现。
- 数据分析与供给:将操作型数据转换为分析型数据,供给数据仓库、数据湖或实时分析系统,支持商业智能和决策。这常常涉及构建独立的数据管道或使用流处理框架。
关键模式与挑战
- 数据库按服务分配:这是微服务的基石,它避免了服务间的数据库耦合,但也意味着传统的跨表JOIN操作不再可行。解决方案包括在应用层进行数据关联、维护只读的冗余数据副本,或使用CQRS(命令查询职责分离)模式。
- 事件驱动的数据一致性:为了在分布式系统中保证最终一致性,广泛采用基于事件的消息传递。例如,订单服务创建订单后发布“OrderCreated”事件,库存服务和支付服务订阅该事件并异步更新自身状态。
- 分布式事务的应对:传统的ACID事务难以跨越多个服务的数据库。Saga模式成为主流解决方案,它通过一系列补偿性操作(Compensating Transactions)来管理长时间运行的事务流程,确保业务过程在出错时可以回滚。
- 数据查询的复杂性:跨多个服务的联合查询是一个挑战。常见的应对策略包括:
- API组合:由网关或专门的组合服务调用多个服务的API,在内存中聚合结果。
- CQRS与物化视图:将写模型(命令端)与读模型(查询端)分离。读模型通过订阅事件流,构建针对特定查询优化、非规范化的物化视图(数据副本),提供极快的查询速度。
技术栈考量
构建数据处理服务时,技术选型需匹配其具体职责:
- 存储层:根据数据特性选择关系型数据库(如PostgreSQL)、文档数据库(如MongoDB)、键值存储(如Redis)或时序数据库等。
- 处理与计算层:对于流式数据处理,可选用Apache Kafka Streams、Apache Flink或Spark Streaming;对于批量ETL,可使用Apache Airflow、dbt等。
- 通信与集成:REST/gRPC用于同步调用,Apache Kafka、RabbitMQ用于异步事件传递。
- 部署与运维:容器化(Docker)与编排(Kubernetes)是实现微服务独立部署和弹性伸缩的标准实践。
###
在微服务架构中,数据处理已从传统的单一数据库中心模式,演变为一个分布式、专业化、协作式的服务体系。成功的关键在于深刻理解领域边界,采用恰当的模式(如事件驱动、CQRS、Saga)来应对分布式数据带来的复杂性,并选择适配的技术栈来实现数据的可靠存储、高效处理与无缝流动。一个设计良好的数据处理服务群,是微服务系统保持高内聚、低耦合、可扩展且健壮运行的坚实数据基石。
如若转载,请注明出处:http://www.dlmkhjc.com/product/43.html
更新时间:2026-02-25 12:11:42